Modelos de bases de datos.
Un modelo de base de datos es un tipo de modelo de datos que determina la estructura lógica de una base de datos y de manera fundamental determina el modo de almacenar, organizar y manipular los datos.Entre los modelos lógicos comunes para bases de datos se encuentran:
- Modelo jerarjico
- Modelo en red
- Modelo relacional
- Modelo entidad-relacion
- Modelo entidad–relación extendido
- Modelo de objetos
- Modelo documental
- Modelo entidad–atributo–valor
- Modelo en extrella
- índice invertido
- fichero plano
- modelo asociativo
- Modelo intedimencional
- modelo multivalor
- modelo semántico
- Base de datos XML
- grafo etiquetado
- Triplestore

Modelo fichero plano

El modelo de fichero plano consiste en una sola matriz bidimensional de elementos, donde todos los miembros en una columna dada tienen valores del mismo tipo, y todos los miembros de la misma fila están relacionados entre ellos. Por ejemplo, las columnas para nombre y clave pueden ser usadas para la seguridad de un sistema; cada fila indicará el nombre y su correspondiente clave para un individuo. Las columnas en la tabla suelen tener un tipo asociado, que la define como cadena de caracteres, fecha u hora, entero o número de coma flotante. Este modelo tabular fue el precursor del modelo relacional.Modelo fichero plano
Modelos tempranos
Estos modelos que se describen a continuación fueron populares en las décadas 1960-1970, pero hoy en día se encuentran sólo en sistemas heredados. Se caracterizan principalmente por tener características de navegación con fuertes conexiones entre la estructura física y la lógica, y poseen alta dependencia en los datos.
Modelo jerárquico
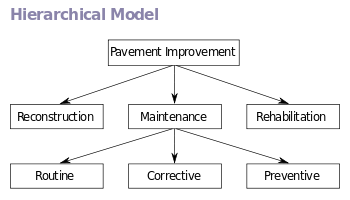
En un modelo jerárquico, los datos están organizados en una estructura arbórea (dibujada como árbol invertido o raíz), lo que implica que cada registro sólo tiene un padre. Las estructuras jerárquicas fueron usadas extensamente en los primeros sistemas de gestión de datos de unidad central, como el Sistema IMS por BIM, y ahora se usan para describir la estructura de documentos XML. Esta estructura permite relaciones 1:N entre los datos, y es muy eficiente para describir muchas relaciones del mundo real: tablas de contenido, ordenamiento de párrafos y cualquier tipo de información anidada.Modelo jerárquico
Sin embargo, la estructura jerárquica es ineficiente para ciertas operaciones de base de datos cuando el camino completo no se incluye en cada registro. Una limitación del modelo jerárquico es su incapacidad para representar de manera eficiente la redundancia en datos.
En la relación Padre-hijo: El hijo sólo puede tener un padre pero un padre puede tener múltiples hijos. Los padres e hijos están unidos por enlaces. Todo nodo tendrá una lista de enlaces a sus hijos.
Modelo de red
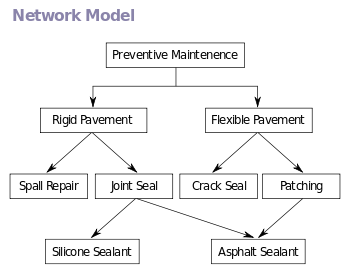
El modelo de red expande la estructura jerárquica, permitiendo relaciones N:N en una estructura tipo árbol que permite múltiples padres. Antes de la llegada del modelo relacional, el modelo en red era el más popular para las bases de datos. Este modelo de red (definido por la especificación CODASYL) organiza datos que usan en dos construcciones básicas, registros y conjuntos. Los registros contienen campos que puede estar organizados jerárquicamente, como en el lenguaje COBOL. Los conjuntos definen relaciones N:N entre registros: varios propietarios, varios miembros. Un registro puede ser un propietario de varios conjuntos, y miembro en cualquier número de conjuntos.Modelo en red
El modelo en red es una generalización del modelo jerárquico, en tanto está construido sobre el concepto de múltiples ramas (estructuras de nivel inferior) emanando de uno o varios nodos (estructuras de nivel alto), mientras el modelo se diferencia del modelo jerárquico en que las ramas pueden estar unidas a múltiples nodos. El modelo de red es capaz de representar la redundancia en datos de una manera más eficiente que en el modelo jerárquico.
Las operaciones del modelo de red se realizan por de navegación: un programa mantiene la posición actual, y navega entre registros siguiendo las relaciones entre ellos. Los registros también pueden ser localizados por valores claves.
Aunque no es una característica esencial del modelo, las bases de datos en red implementan sus relaciones mediante punteros directos al disco. Esto da una velocidad de recuperación excelente, pero penaliza las operaciones de carga y reorganización.
Entre los SGBD más populares que tienen arquitectura en red se encuentran Total e IDMS. IDMS logró una importante base de usuarios; en 1980 adoptó el modelo relacional y SQL, manteniendo además sus herramientas y lenguajes originales.
La mayoría de bases de datos orientados a objetos (introducidas en 1990) usan el concepto de navegación para proporcionar acceso rápido entre objetos en una red. Objectivity/DB, por ejemplo, implementa 1:1, 1:N, N:1 y N:N entre distintas bases de datos. Muchas bases de datos orientadas a objetos también soportan SQL, combinando así la potencia de ambos modelos.
Modelo de fichero invertido
En un fichero invertido o de índice invertido, los datos contenidos se usan como claves en una tabla de consulta (lookup table), y los valores en la tabla se utilizan como punteros a la localización de cada instancia. Esta es también la estructura lógica de los índices de bases de datos modernas, los cuales introducen sólo el contenido de algunas columnas en esa tabla de consulta. El modelo de fichero invertido puede poner los índices en ficheros planos para acceder a sus registros de manera eficiente.
Implementaciones notables de este modelo de datos la realizó Adabas de Software AG, aparecida en 1970. Adabas logró una importante base de usuarios y está soportada aún hoy. En la década de 1980 adoptó el modelo relacional y SQR, manteniendo sus propias herramientas y lenguajes.

Modelo dimensional
El modelo dimensional es una adaptación especializada del modelo relacional usada para almacenar datos en depósitos de datos, de modo que los datos fácilmente puedan ser extraídos usando consultas OLAP. En el modelo dimensional, una base de datos consiste en una sola tabla grande de datos que son descritos usando dimensiones y medidas. Una dimensión proporciona el contexto de un hecho (como quien participó, cuando y donde pasó, y su tipo). Las dimensiones se toman en cuenta en la formulación de las consultas para agrupar hechos que están relacionados. Las dimensiones tienden a ser discretas y son a menudo jerárquicas; por ejemplo, la ubicación podría incluir el edificio, el estado y el país. Una medida es una cantidad que describe el dato, tal como los ingresos. Es importante que las medidas puedan ser agregados significativamente -por ejemplo, los ingresos provenientes de diferentes lugares puedan sumarse.
En una consulta OLAP, las dimensiones y los hechos son agrupados y añadidos juntos para crear un informe. El modelo dimensional a menudo es puesto en práctica sobre el modelo relacional usando un esquema de estrella, consistiendo en una tabla que contiene los datos y tablas circundantes que contienen las dimensiones. Dimensiones complicadas podrían ser representadas usando múltiples tablas, usando un esquema de copo de nieve.
Un almacén de datos puede contener múltiples esquemas de estrella que comparten tablas de dimensión, permitiéndoles ser usadas juntas. El establecimiento de un conjunto de dimensiones estándar es una parte importante del modelado dimensional.
Modelos post-relacionales
Los productos que ofrecen un modelo de datos más general que el relacional se denominan a veces post-relational. Como términos alternativos se oyen incluyen "bases de datos híbridas", "bases de datos relacionales potenciadas con objetos" entre otros. El modelo de datos de esos productos incorpora relaciones pero no limitadas por las restricciones del principio de información de E.F codd, que requiere que toda información en la base de datos debe ser modelada en términos de valores en relaciones nada más3
Algunas de estas extensiones al modelo relacional integran conceptos de tecnologías que preceden el modelo relacional. Por ejemplo permiten representar un grafo dirigido con árboles en los nodos. La compañía sones implementa este concepto en su GraphDB.
Algunos productos post-relacionales amplían los sistemas relacionales con caracterśiticas no relacionales. Otros han llegado al mismo punto añadiendo características relacionales a modelos pre-relacionales. Paradójicamente esto ha permitido a productos históricamente pre-relacionales, como por ejemplo PICK y MUMPS, razonar su esencia post-relactional.
El Resource Space Model es un modelo de datos no relacional basado en clasificación multi-dimensional.
Modelo de grafo
Las bases de datos de grafos permiten incluso una estructura más general que una base de datos en red, cualquier nodo puede estar conectado a cualquier otro.
Modelo multivaluados
Las bases de datos multivaluadas contienen datos arracimados, en el sentido de que pueden almacenar los datos del mismo modo que las bases de datos relacionales, pero además permiten un nivel de profundidad al que las relacionales sólo se pueden aproximar utilizando subtablas. Esto es prácticamente igual al modo en que XML representa los datos, donde un campo/atributo dado puede contener múltiples valores a la vez. El multivalor se puede considerar una forma de XML comprimida.
Un ejemplo puede ser una factura, la que puede ser vista como:
- Encabezado, una entrada por factura
- Detalle, una entrada por concepto




Tiene la ventaja que la correspondencia entre la factura conceptual y la de la factura como representación de datos es biunívoca. Esto redunda en menor número de lecturas, menos problemas de integridad referencial y una fuerte disminución del hardware necesario para soportar un volumen de transacciones dado.
Modelo orientado a objetos

Modelo orientado a objetos:
No hay comentarios.:
Publicar un comentario